개요
Xillybus의 가장 일반적인 사용 시나리오는 data acquisition입니다. 이 페이지는 FPGA 에서 host로 data 전송을 시작하는 방법을 보여줍니다.
FPGA내부의 Xillybus 와의 상호 작용에 대한 자세한 내용은 Xillybus FPGA designer's guide를 참조하십시오.
애플리케이션의 data rate가 높으면 Getting Started guide for Linux 의 5장이나 Microsoft Windows에 대한 지침을 읽어보는 것이 좋습니다.
host의 측면
Xillybus 의 작동 방식을 이해하려면 컴퓨터 쪽에서 시작하는 것이 가장 쉽습니다. 이 command는 디스크의 파일에 data acquisition을 수행하는 데 사용할 수 있습니다.
$ cat /dev/xillybus_read_32 > capture-file.dat
"cat"는 파일에서 모든 data를 읽고 이 data를 standard output에 쓰는 표준 Linux command 입니다. 이 예에서 입력은 일반 파일이 아니라 device file입니다. 이 입력은 FPGA에서 도착한 data stream 로 구성됩니다. standard output의 redirection이 있으므로 이 data는 디스크의 파일에 쓰여집니다.
이것은 인공적인 예가 아닙니다. 일부 사용 시나리오에서는 data acquisition용으로 Xillybus를 실제로 사용하는 올바른 방법입니다. 특정 양의 data를 얻으려면 "dd"를 사용하는 것이 좋습니다. 더 자주 전용 컴퓨터 프로그램을 사용하여 device file에서 data를 읽습니다. 각 애플리케이션에는 data를 사용하는 선호하는 방법이 있습니다.
따라서 어떤 프로그래밍 언어를 선호하거나 Linux 또는 Windows를 사용하는지는 중요하지 않습니다. FPGA 에서 data를 수신하는 컴퓨터 소프트웨어는 "cat"와 동일하게 수행하면 됩니다. 파일을 열고 읽습니다. file I/O에 대한 표준 프로그래밍 기술을 소개하는 별도의 페이지가 있습니다. Xillybus를 사용한 프로그래밍 기술에 대한 더 자세한 정보는 Linux 및 Windows용 프로그래밍 가이드에서 찾을 수 있습니다.
data acquisition용 logic
이제 FPGA에서 어떤 일이 일어나는지 살펴보겠습니다. Xillybus IP core 와 application logic은 FIFO를 통해 상호 작용합니다. application logic은 data를 FIFO에 기록하고 Xillybus는 이 data가 host에 도달하도록 합니다. 이 개념에 익숙하지 않은 경우 FIFOs 작동 방식을 설명하는 별도의 페이지가 있습니다.
Xillybus의 demo bundle 에는 xillydemo.v라는 파일이 들어 있습니다. 이것은 IP core와 인터페이스하는 Verilog code 입니다. demo bundle에도 VHDL 파일이 있습니다. xillydemo.vhd. 단, 아래 예시는 Verilog기준입니다.
Xillybus IP core의 instantiation은 xillydemo.v에서 일어납니다. (또는 xillydemo.vhd). 이것들은 위의 "cat" command 와 관련된 data acquisition 예와 관련된 부분입니다(다른 부분은 건너뜁니다).
// Wires related to /dev/xillybus_read_32
wire user_r_read_32_rden;
wire user_r_read_32_empty;
wire [31:0] user_r_read_32_data;
wire user_r_read_32_eof;
wire user_r_read_32_open;
[ ... ]
xillybus xillybus_ins (
[ ... ]
// Ports related to /dev/xillybus_read_32
// FPGA to CPU signals:
.user_r_read_32_rden(user_r_read_32_rden),
.user_r_read_32_empty(user_r_read_32_empty),
.user_r_read_32_data(user_r_read_32_data),
.user_r_read_32_eof(user_r_read_32_eof),
.user_r_read_32_open(user_r_read_32_open),
[ ... ]
.bus_clk(bus_clk),
[ ... ]
);
IP core의 ports 의 의미는 Xillybus의 logic API가이드 에 자세히 설명되어 있습니다.
xillydemo.v에는 FIFO 의 instantiation이 있습니다. 이 FIFO는 single-clock FIFO가 며, 원래 Verilog code에서 시연된 loopback 에 적합합니다. data acquisition 애플리케이션의 경우 dual-clock FIFO가 더 적합한데, data acquisition logic은 일반적으로 자체 clock에 의존하기 때문입니다.
따라서 다음과 같이 xillydemo.v를 data acquisition을 수행하는 module 로 변경할 수 있습니다. single-clock FIFO 의 instantiation을 삭제합니다( fifo_32x512라고 함). 대신 다음을 삽입하십시오.
assign user_r_read_32_eof = 0;
dualclock_fifo_32 fifo_32
(
.rd_clk(bus_clk),
.rst(!user_r_read_32_open),
.rd_en(user_r_read_32_rden),
.dout(user_r_read_32_data),
.empty(user_r_read_32_empty)
.wr_clk(capture_clk),
.wr_en(capture_en),
.din(capture_data),
.full(capture_full)
);
dual-clock FIFO
dualclock_fifo_32는 standard dual-clock FIFO입니다. FPGA의 개발 소프트웨어로 IP 로 만들어야 합니다. 이 FIFO 의 깊이는 512 elements 이상이어야 합니다. FPGA 소프트웨어 간의 차이로 인해 ports 의 이름은 위에 표시된 것과 다를 수 있습니다. 그럼에도 불구하고 FIFO의 ports를 연결하는 방법은 쉽게 추론할 수 있을 것입니다.
다시 한 번 FIFOs에 익숙하지 않은 경우 소개하는 페이지가 있습니다.
FIFO의 ports 중 일부는 Xillybus의 IP core에 직접 연결됩니다. @rd_clk, @rd_en, @dout 및 @empty. 이러한 연결은 demo bundle에서와 정확히 동일하게 이루어집니다. IP core는 이 4개의 signals를 사용하여 FIFO에서 data를 가져옵니다. 이것은 ports를 IP core와 연결하는 올바른 방법입니다.
@rd_clk은 @bus_clk에 연결되어 있습니다. 이 signal은 Xillybus의 IP core에서 가져온 것입니다. 즉, IP core는 FIFO의 측면 중 하나에서 사용되는 clock을 지시합니다.
@rst의 경우 !user_r_read_32_open에 연결되어 있습니다. @user_r_read_32_open은 관련 device file이 host에서 열려 있을 때만 높음입니다. 결과적으로 파일이 열려 있지 않으면 FIFO가 재설정됩니다. 따라서 host가 device file을 열 때 FIFO는 비어 있습니다. 이전 세션에서 FIFO스토리지에 남은 항목이 있는 경우 device file을 닫을 때 삭제되었습니다.
이 동작은 일반적으로 data소스에서 예상되는 동작입니다. 그러나 device file이 닫힐 때 FIFO가 data를 유지하도록 하려면 다른 것을 @rst에 연결하십시오. 또는 @rst를 낮게 유지할 수도 있습니다.
이 예와 demo bundle에서 @user_r_read_32_eof는 0입니다. 이 signal은 end-of-file을 host로 보내는 데 사용할 수 있습니다. 이에 대한 자세한 내용은 API가이드를 참조하세요.
application logic와의 인터페이스
data acquisition 애플리케이션에는 항상 host로 전송하기 위해 data를 생성하는 일종의 application logic이 있습니다. 이 부분은 애플리케이션마다 다르기 때문에 이 논의와 관련이 없습니다. 이 data를 host로 보내는 데 중점을 둘 것입니다.
이 부분은 놀라울 정도로 쉽습니다. application logic은 이 data를 FIFO에 씁니다. FIFO 에 기록된 data는 host 의 컴퓨터 프로그램에 연속적인 data stream로 도착합니다.
따라서 application logic은 FIFO에 쓰기 위한 표준 규칙을 사용합니다. 위의 예에서는 @capture_clk, @capture_en, @capture_data 및 @capture_full로 표시됩니다. 이 logic은 FIFO에 올바르게 쓰기 위해 data를 @capture_data 에 넣고 @capture_en을 제어하기만 하면 됩니다. application logic은 FIFO에 쓰기 위해 자체 clock을 사용합니다.
data flow
이것은 application logic 에서 host의 user application program 까지의 data flow를 보여주는 단순화된 블록 다이어그램입니다.
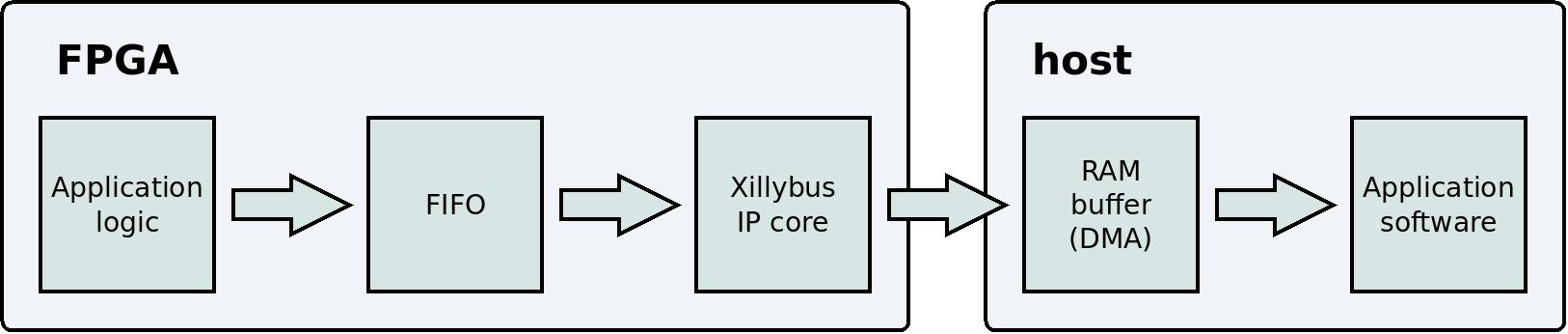
이 블록 다이어그램에서 두 가지 기술적 세부 사항이 생략되었습니다. PCIe block 및 kernel driver는 data flow에 대한 사용자의 인식과 관련이 없기 때문에 표시되지 않았습니다. Xillybus를 사용하는 올바른 방법은 이러한 세부 사항을 잊고 application logic 및 application software에 집중하는 것입니다.
data를 packets로 구성할 필요가 없습니다. application logic 와 컴퓨터 간의 통신 채널은 연속적인 stream입니다. IP core 와 driver는 data flow가 다른 stream protocols처럼 동작하도록 보장합니다. 예를 들어 programs 와 Linux간의 pipes 입니다. 비슷한 동작을 하는 또 다른 protocol은 TCP/IP입니다. 다시 말해, data가 FIFO에 얼마나 많이 쓰여지는지는 중요하지 않습니다. 이 data는 곧 host에서 user application program 에 도달할 것입니다.
data를 packets 로 구성하고 IP core의 DMA buffers를 이러한 packets의 크기에 맞추는 것은 흔한 실수입니다. 이렇게 하면 이점이 없습니다. data가 일정한 크기의 packets 로 전송되더라도 IP core를 이 크기에 맞출 필요가 없습니다.
하지만 FIFO가 가득 차면 어떻게 될까요?
FIFO 에 대한 기본 규칙 중 하나는 다음과 같습니다. @full port가 높으면 @wr_en 도 낮아야 합니다. 간단히 말해서: 전체 FIFO에 쓰지 마십시오. 그렇다면 어떻게 될까요? 이 상황을 처리하면 application logic이 상당히 복잡해집니다.
짧은 대답은 FIFO가 가득 차서는 안 된다는 것입니다. 정상 작동 조건에서는 다음과 같이 능동적으로 방지됩니다. IP core는 FIFO 에서 data를 읽고 이 data를 host의 RAM로 복사합니다. 이것은 FIFO가 채워지는 것을 방지할 만큼 충분히 빠르게 발생합니다. 일반적으로 FIFO는 512 data elements보다 깊을 필요가 없습니다.
그러나 application logic이 FIFO 에 너무 빨리 쓰면 FIFO가 가득 찰 수 있습니다. 즉, application logic의 평균 data rate가 IP core의 제한을 초과하면( IP core의 각 유형에 대해 광고된 대로) IP core는 FIFO에서 data를 충분히 빠르게 읽을 수 없습니다.
또 다른 가능성은 user application software (예: 위의 예에서 "cat")가 device file에서 data를 충분히 빨리 읽지 못한다는 것입니다. 그 결과, host 에서 RAM buffer가 가득 차게 되고, 이 역시 IP core가 FIFO 에서 읽을 수 없게 됩니다( IP core가 data를 쓸 곳이 없기 때문입니다). 그 결과, overflow가 발생합니다. 이는 user application software가 잘못 작성되었기 때문에 발생할 수 있습니다. 또 다른 가능한 이유는 운영 체제와 관련이 있으며, 이에 대해서는 아래에서 자세히 설명합니다.
host 의 RAM buffer 크기는 Xillybus IP Core에 따라 다릅니다. 예를 들어, 이 크기는 xillybus_read_32 및 xillybus_write_32 의 경우 4 MBytes 입니다( demo bundle의 일부인 IP core 에서). IP Core Factory를 사용하면 훨씬 더 큰 buffers를 요청하는 맞춤형 IP cores를 만들 수 있습니다.
결론적으로: overflow를 방지하는 것은 IP core에 대한 올바른 매개변수를 선택하는 문제입니다. 무엇보다도, 이 IP core는 data rate를 처리할 수 있어야 합니다. 게다가 host의 RAM buffer는 충분히 커야 합니다. 이렇게 하면 user application program이 device file에서 data를 읽지 않더라도 데이터 흐름이 계속될 수 있습니다.
이 모든 것에도 불구하고 FIFO가 꽉 찼다면 일반적인 이유는 system design의 실수입니다. overflow를 사용하는 일반적인 이유는 컴퓨터가 data rate를 처리하는 능력을 과대평가하기 때문입니다.
특히, data가 디스크의 파일에 기록되는 경우(위의 "cat" command 와 같이), 최대 data rate는 생각보다 느릴 수 있습니다. 그 이유는 운영 체제에 종종 큰 disk cache (아마도 많은 Gigabytes)가 있기 때문입니다. 디스크의 data rate가 disk cache보다 작은 양의 data 로 측정되는 경우 결과가 너무 낙관적일 것입니다. 운영 체제는 이것이 실제로 발생하기 전에 디스크에 data 쓰기를 완료한 것처럼 가장합니다. 실제로 data는 cache에만 도달하며 디스크에 대한 실제 쓰기는 나중에 발생합니다. 이 실수는 더 많은 양의 data를 처리해야 드러납니다.
CPU의 박탈
불행히도 overflow에는 불가피한 가능성이 있습니다. 운영 체제(Linux 또는 Windows)는 무제한 시간 동안 CPU 의 모든 user-space process를 박탈할 수 있습니다. 즉, data를 읽는 컴퓨터 프로그램이 일정 시간 동안 갑자기 작동을 멈춘 다음 정상 작동을 재개할 수 있습니다. 이 기간에는 제한이 없습니다. 모든 non-real-time operating system은 이와 같이 임의로 processes를 일시 중지할 수 있습니다.
그럼에도 불구하고 data acquisition은 이러한 운영 체제에서 여전히 가능합니다. 이것은 주로 CPU 의 오랜 박탈이 일반적으로 나쁜 특성으로 간주되기 때문입니다. 따라서 이러한 일시 중지는 일반적으로 짧습니다.
이러한 일시 중지 동안 IP core는 host 의 RAM buffer를 계속 채웁니다( DMA덕분에 processor의 개입이 필요하지 않음). 컴퓨터 프로그램이 CPU를 되찾으면 축적된 모든 data를 빠르게 소비할 수 있습니다. 일반적으로 10 ms 일시 중지를 보상하는 RAM buffer가 면 충분합니다. 그러나 IP Core Factory 에서 맞춤형 IP core를 만들 때 훨씬 더 큰 buffer를 요청할 수 있습니다.
즉, 일시 중지가 너무 길어질 가능성이 여전히 있습니다. 결과적으로 RAM buffer가 가득 차게 되고 결과적으로 FPGA 의 FIFO가 가득 차게 됩니다. 이 overflow 의 결과는 data가 손실된다는 것입니다. 이것은 절대 일어나서는 안되며, 아마 절대 일어나지 않을 것입니다. 하지만 만약 그렇다면?
overflow감지
제안된 솔루션은 FIFO가 가득 차면 data stream을 종료하는 것입니다. logic은 인접한 data의 마지막 요소 바로 뒤에 EOF (end-of-file)를 host 로 보냅니다. 따라서 위에서 제안한 대로 host가 "cat" command로 data를 소비하면 어떤 일이 일어나는지 고려해 보겠습니다.
$ cat /dev/xillybus_read_32 > capture-file.dat
일반적으로 이 command는 CTRL-C로 멈출 때까지 계속됩니다. 하지만 FIFO가 FPGA에서 가득 찼다면 이 command는 일반 파일을 복사한 후와 마찬가지로 정상적으로 종료됩니다. 출력 파일에는 FIFO가 가득 찼기 전에 수집된 모든 data가 포함됩니다.
이 방법을 요약하면 다음과 같습니다. capture-file.dat 에 기록되는 모든 data는 오류가 없고 연속적임을 보장합니다. data acquisition 시스템이 CPU 부족으로 인해 연속성을 유지하지 못하는 경우 출력 파일이 더 짧아집니다. 그러나 파일의 내용은 신뢰할 수 있습니다.
이 솔루션을 구현하려면 dualclock_fifo_32의 instantiation을 다음으로 교체하십시오.
eof_fifo fifo_32
(
.rd_clk(bus_clk),
.rst(!user_r_read_32_open),
.rd_en(user_r_read_32_rden),
.dout(user_r_read_32_data),
.empty(user_r_read_32_empty)
.wr_clk(capture_clk),
.wr_en(capture_en),
.din(capture_data),
.full(),
.eof(user_r_read_32_eof)
);
eof_fifo 의 정의는 별도의 페이지 에 나와 있습니다.
참고로 @user_r_read_32_eof는 이 FIFO의 @eof port에 연결되어 있습니다. logic이 필요할 때 EOF를 host 로 보내는 방식입니다. 또한 이 FIFO의 @full port에는 아무 것도 연결되어 있지 않습니다. 더 이상 이 signal을 모니터링할 필요가 없습니다. FIFO가 가득 차면 할 수 있는 일이 많지 않습니다. EOF 메커니즘은 모든 유효한 데이터가 소비된 후 host가 데이터 흐름을 다시 시작하도록 합니다.
Data playback
반대 방향은 어떻습니까? 이와 같은 것은 어떻습니까?
$ cat playback-data.dat > /dev/xillybus_write_32
이것은 동일한 원리로 작동합니다. "cat" command는 디스크의 파일을 읽고 data를 device file에 씁니다. FPGA에서 IP core는 이 data를 FIFO에 씁니다. application logic은 FIFO에서 data를 읽습니다. 같은 아이디어지만 반대 방향입니다.
이것은 host 의 user application program 에서 application logic까지 data flow를 보여주는 단순화된 블록 다이어그램입니다.
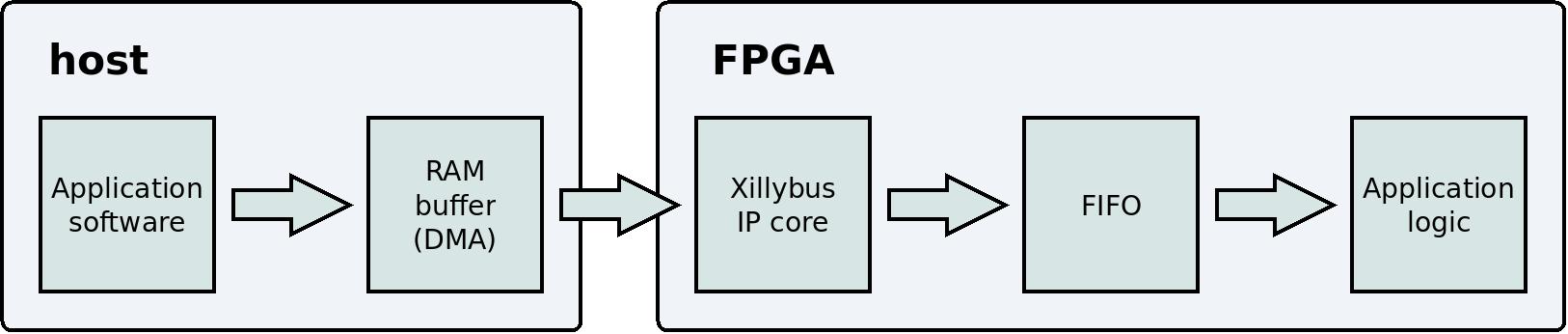
data acquisition와 유사하게 data의 손실 위험이 없습니다. IP core는 가득 차면 FIFO 에 쓰지 않습니다. 결과적으로 host의 RAM 에 있는 buffer 도 꽉 찰 수 있습니다. 이런 일이 발생하면 host 의 user application program은 application logic이 FIFO에서 충분한 data를 읽을 때까지 대기합니다(잠자기).
data acquisition 의 또 다른 유사점은 user application program이 계속해서 data를 충분히 빠르게 작성하는 한 FIFO가 비워지지 않는다는 것입니다. 이를 보장하기 위해 동일한 고려 사항이 관련됩니다. IP core의 사양과 user application program은 필수 data rate를 지원해야 합니다.
이러한 조건이 충족되면 application logic은 이 data가 필요할 때 FIFO 에서 data를 사용할 수 있습니다. underflow는 절대 발생해서는 안 됩니다.
Asynchronous streams 대 Synchronous streams
이 항목은 직접적으로 관련이 없지만 간략하게 논의할 가치가 있습니다.
data acquisition 애플리케이션에서 주요 목표는 지속적인 데이터 흐름을 유지하는 것입니다. 따라서 IP core는 가능한 한 빨리 data를 FIFO 에서 host의 RAM buffer 로 옮깁니다. host 의 user application program이 주어진 순간에 data를 요청하는지는 중요하지 않습니다( read() 또는 이와 유사한 함수 호출을 통해): device file이 열려 있고 FIFO에 data가 있는 한 데이터 흐름은 계속됩니다.
즉, host는 FPGA 에서 data flow를 제어할 방법이 없습니다( device file을 열고 닫거나 애플리케이션별 솔루션을 사용하는 경우 제외). 그러나 대부분의 실제 data acquisition 애플리케이션에서는 데이터 흐름을 제어할 필요가 없습니다. 데이터 흐름이 device file을 여는 결과로 시작되는 것은 괜찮습니다. 각 데이터 요소가 FIFO에서 정확히 언제 읽혔는지는 중요하지 않습니다.
이와 같이 작동하는 device file을 asynchronous stream ( Xillybus용어로)라고 합니다.
그러나 다른 응용 프로그램에서는 data를 수집한 시기가 중요합니다. 예를 들어, FPGA 의 application logic은 FIFO에서 data 대신 status register 의 콘텐츠를 보낼 수 있습니다. 이것은 xillybus_mem_8라는 device file 와 함께 demo bundle 에서 시연됩니다. 이 경우 data가 FPGA에서 수집되는 시기를 제어하는 것이 매우 중요합니다. host는 과거의 어느 시점의 상태가 어땠는지가 아닌, 그 순간의 상태에 대한 정보를 얻기 위해 device file 에서 정보를 읽습니다.
Xillybus 에는 다음과 같은 종류의 애플리케이션을 위한 synchronous streams가 있습니다. IP core는 항상 FPGA에서 가능한 한 적은 data를 수집합니다. 즉, IP core는 host에서 read() (또는 유사)에 대한 함수 호출에 대한 응답으로만 data를 수집합니다. 따라서 host는 data가 FPGA에서 수집되는 시기를 제어합니다.
synchronous streams 의 단점은 데이터 흐름의 일시 정지입니다. 이러한 일시 정지의 주요 문제는 데이터 흐름이 일시적으로 중단되면 FPGA 의 FIFO가 가득 찰 수 있다는 것입니다. 이러한 일시 정지는 또한 데이터 흐름의 효율성을 떨어뜨려 최대 data rate가 낮아집니다. 그러나 이 두 가지 단점은 data acquisition 애플리케이션에만 해당됩니다. 그러한 애플리케이션은 어쨌든 asynchronous stream을 사용해야 합니다.
반대 방향의 device files 에 관해서도 asynchronous streams 와 synchronous streams사이에는 차이가 있습니다. 이 방향에서 차이점은 write() 함수 호출의 반환에 있습니다. asynchronous streams의 경우 data가 RAM buffer에 기록되자마자 write()가 반환됩니다. 따라서 대부분의 경우 write()는 전혀 잠들지 않습니다. 반면에 synchronous streams의 경우 write()는 data가 FPGA에 전달될 때까지 기다립니다. 이는 통신 채널을 사용하여 명령을 보낼 때 중요합니다. 그러나 다시 한 번 이것은 data acquisition 애플리케이션에 좋지 않습니다.
demo bundle에서 /dev/xillybus_mem_8 만 synchronous stream입니다. 다른 4개의 device files는 asynchronous streams입니다.
IP Core Factory 에서 synchronous stream 또는 asynchronous streams 사이의 선택은 애플리케이션 선택에 따라 다릅니다("use"의 경우 drop-down menu ). 예를 들어 "Data acquisition / playback"를 선택하면 도구에서 asynchronous streams를 생성합니다. "Command and status"를 선택하면 synchronous stream을 얻게 됩니다. "Autoset internals"를 꺼서 수동으로 선택할 수도 있습니다.
asynchronous streams 및 synchronous streams에 대한 자세한 내용은 programming guide for Linux (또는 programming guide for Windows )의 섹션 2를 참조하십시오. IP Core Factory에 대해서는 guide to defining a custom Xillybus IP core를 참조하십시오.
요약
간단하면서도 실용적으로 기능적인 data acquisition system은 Xillybus를 사용하여 간단하고 빠르게 만들 수 있습니다. application software는 표준 Linux command ("cat")를 사용하는 것으로 귀결됩니다. FPGA측에서 Xillybus의 IP core 와의 상호 작용은 data를 FIFO에 쓰는 것으로만 구성됩니다.
Xillybus 로 수집된 data는 오류가 없고 연속적임을 보장합니다. 그러나 운영 체제의 특성상 overflow가 절대 발생하지 않는다는 보장은 없습니다. 이는 불가피하므로 최적의 접근 방식은 overflow가 발생할 경우 감지를 보장하는 것입니다. Xillybus는 EOF를 host로 전송함으로써 이러한 목적을 위한 간단한 메커니즘을 제공합니다.