概要
Xillybusの最も一般的な使用シナリオは data acquisitionです。このページでは、 FPGA から hostへの data の送信を開始する方法を示します。
FPGA内の Xillybus との相互作用の詳細については、 Xillybus FPGA designer's guideを参照してください。
アプリケーションの data rateが高い場合は、 Getting Started guide for Linux の第 5 章または Microsoft Windowsのガイドラインも読むことをお勧めします。
hostの側面
Xillybus がどのように機能するかを理解するには、コンピューター側から始めるのが最も簡単です。 この command は、ディスク上のファイルに data acquisition を実行するために使用できます。
$ cat /dev/xillybus_read_32 > capture-file.dat
「cat」は、ファイルからすべての data を読み取り、この data を standard outputに書き込む標準の Linux command です。この例では、入力は通常のファイルではなく、 device fileです。この入力は、 FPGAから到着する data stream で構成されています。 standard outputの redirection があるため、この data はディスク上のファイルに書き込まれます。
これは人工的な例ではありません: 一部の使用シナリオでは、これが実際に Xillybus を data acquisitionに使用する正しい方法です。 dataを一定量手に入れるには「dd」を使ったほうがいいかもしれません。多くの場合、専用のコンピューター プログラムを使用して、 device fileから data を読み取ります。各アプリケーションには、 dataを使用する独自の推奨方法があります。
したがって、どのプログラミング言語を好むか、または Linux と Windowsのどちらを使用するかは問題ではありません。 FPGA から data を受信するコンピュータ ソフトウェアは、「cat」と同じことを行うだけで済みます。 ファイルを開き、そこから読み取ります。 file I/Oの標準的なプログラミング手法を紹介する別のページがあります。 Xillybus でのプログラミング手法に関するさらに詳細な情報は、 Linux および Windowsのプログラミング ガイドに記載されています。
data acquisitionのための logic
では、 FPGAで何が起こるか見てみましょう。 Xillybus IP core と application logic は FIFOを介して対話します。 application logic は data を FIFOに書き込み、 Xillybus はこの data が hostに到達することを確認します。この概念に慣れていない場合は、 FIFOs がどのように機能するかを説明する別のページがあります。
Xillybusの demo bundle には、 xillydemo.vというファイルが含まれています。これは、 IP coreとインターフェイスする Verilog code です。 demo bundleには、 VHDL ファイルもあります。 xillydemo.vhd.ただし、以下の例は Verilogのものです。
Xillybus IP coreの instantiation は xillydemo.vで発生します。(または xillydemo.vhd)。これらは、上記の "cat" command の data acquisition の例に関連する部分です (他の部分はスキップされます)。
// Wires related to /dev/xillybus_read_32
wire user_r_read_32_rden;
wire user_r_read_32_empty;
wire [31:0] user_r_read_32_data;
wire user_r_read_32_eof;
wire user_r_read_32_open;
[ ... ]
xillybus xillybus_ins (
[ ... ]
// Ports related to /dev/xillybus_read_32
// FPGA to CPU signals:
.user_r_read_32_rden(user_r_read_32_rden),
.user_r_read_32_empty(user_r_read_32_empty),
.user_r_read_32_data(user_r_read_32_data),
.user_r_read_32_eof(user_r_read_32_eof),
.user_r_read_32_open(user_r_read_32_open),
[ ... ]
.bus_clk(bus_clk),
[ ... ]
);
IP coreの ports の意味は、Xillybusの logic APIガイドで詳しく説明されています。
xillydemo.vには FIFO の instantiation があります。この FIFO は single-clock FIFOであり、オリジナルの Verilog codeで実証されている loopback に適しています。 data acquisition アプリケーションの場合、 data acquisition logic は通常独自の clockに依存するため、 dual-clock FIFO の方が適しています。
したがって、次のように xillydemo.v を data acquisition を実行する module に変更できます。 single-clock FIFO の instantiation を削除します ( fifo_32x512と呼ばれます)。代わりにこれを挿入します:
assign user_r_read_32_eof = 0;
dualclock_fifo_32 fifo_32
(
.rd_clk(bus_clk),
.rst(!user_r_read_32_open),
.rd_en(user_r_read_32_rden),
.dout(user_r_read_32_data),
.empty(user_r_read_32_empty)
.wr_clk(capture_clk),
.wr_en(capture_en),
.din(capture_data),
.full(capture_full)
);
dual-clock FIFO
dualclock_fifo_32 は standard dual-clock FIFOです。 FPGAの開発ソフトウェアを使用して、 IP として作成する必要があります。この FIFO の深さは 512 elements 以上である必要があります。 FPGA ソフトウェアの違いにより、 ports の名前は上記と異なる場合があります。それでも、 FIFOの portsを接続する方法は簡単に推測できるはずです。
FIFOsにまだ慣れていない方のために、もう一度 FIFOsを紹介するページがあります。
FIFOの ports のいくつかは、 Xillybusの IP coreに直接接続されています。 @rd_clk、 @rd_en、 @dout 、 @empty。これらの接続は、 demo bundleとまったく同じであることに注意してください。 IP core は、これら 4 つの signals を使用して、 FIFOから data を引き出します。これは常に、これらの ports を IP coreに接続する正しい方法です。
@rd_clk は @bus_clkに接続されていることに注意してください。この signal は、 Xillybusの IP coreから派生したものです。つまり、 IP core は、 FIFOのいずれかの側で使用される clock を決定します。
@rstに関しては、 !user_r_read_32_openに接続されていることに注意してください。 @user_r_read_32_open は、関連する device file が hostで開いている場合にのみハイになります。その結果、ファイルが開かれていないときに FIFO がリセットされます。したがって、 host が device fileを開くと、 FIFO は空になります。 以前のセッションから FIFOのストレージに残り物があった場合、それらは device file が閉じられたときに削除されました。
この動作は、 dataのソースから通常期待されるものです。ただし、 device file を閉じたときに FIFO に data を保持させたい場合は、別のものを @rstに接続します。または、 @rst を低く保持することもできます。
この例と demo bundleでは、 @user_r_read_32_eof がゼロであることに注意してください。この signal を使用して、 end-of-file を hostに送信できます。これについては、 APIのガイドを参照してください。
application logicとのインターフェース
data acquisition アプリケーションでは、 hostへの送信用に data を生成するある種の application logic が常に存在します。この部分はアプリケーションごとに異なるため、この説明には関係ありません。この data を hostに送信することに焦点を当てます。
この部分は驚くほど簡単です。 application logic は、この data を FIFOに書き込みます。 FIFO に書き込まれた data は、連続した data streamとして host 上のコンピューター プログラムに到達します。
したがって、 application logic は、 FIFOへの書き込みに標準的な規則を使用します。上記の例では、これは @capture_clk、 @capture_en、 @capture_data 、および @capture_fullで示されています。この logic は、 FIFOに正しく書き込むために、 data を @capture_data に入れ、 @capture_en を制御するだけで済みます。 application logic は、 FIFOへの書き込みに独自の clock を使用することに注意してください。
data flow
これは、 host上の application logic から user application program までの data flow を示す単純化されたブロック図です。
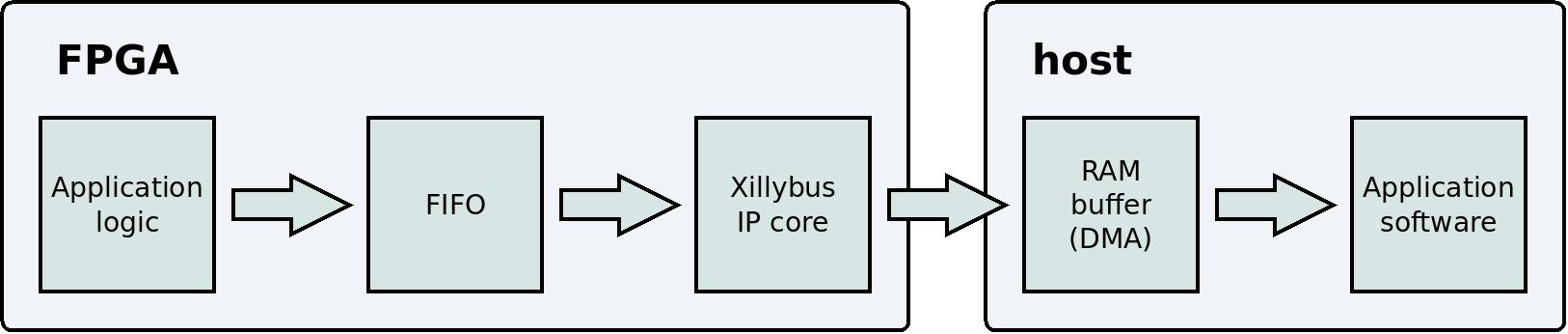
このブロック図では、次の 2 つの技術的な詳細が省略されていることに注意してください。 PCIe block と kernel driver は、ユーザーの data flowに対する認識とは無関係であるため、表示されていません。 Xillybus を使用する正しい方法は、これらの詳細を忘れて、 application logic と application softwareに集中することです。
data を packetsに編成する必要はありません。 application logic とコンピュータ間の通信チャネルは連続した streamです。 IP core と driver により、 data flow は他の stream protocolsと同様に動作します (例: Linux内の programs 間の pipes )。同様の動作をする別の protocol は TCP/IPです。つまり、 FIFOにどれだけの data が書き込まれても問題ありません。この data はすぐに host上の user application program に到達します。
data を packets に編成し、 IP coreの DMA buffers をこれらの packetsのサイズに適合させるのはよくある間違いです。これを行う利点はありません。 data が固定サイズの packets で送信された場合でも、 IP core をこのサイズに合わせる必要はありません。
しかし、 FIFO がいっぱいになったらどうしますか?
FIFO に関する基本的なルールの 1 つは次のとおりです。 @full port が高い場合、 @wr_en は低くなければなりません。簡単に言えば: 完全な FIFOに書き込まないでください。それで、それが起こったらどうしますか?この状況を処理すると、 application logic はかなり複雑になります。
簡単に言えば、 FIFO がいっぱいになることはありません。 通常の操作条件下では、これはアクティブに防止されます。 IP core は FIFO から data を読み取り、この data を hostの RAMにコピーします。これは、 FIFO がいっぱいになるのを防ぐのに十分な速さで発生します。通常、 FIFO は 512 data elementsより深くする必要はありません。
ただし、 application logic から FIFO への書き込みが速すぎると、 FIFO がいっぱいになることがあります。言い換えれば、 application logicの平均 data rate が IP coreの制限 ( IP coreの各タイプで宣伝されている) を超えた場合、 IP core は FIFOから十分に速く data を読み取ることができなくなります。
もう 1 つの可能性は、 user application software (上記の例では「cat」) が device fileから data を十分な速さで読み取っていないことです。その結果、 host の RAM buffer がいっぱいになり、これもまた IP core が FIFO から読み取ることを妨げることになります ( IP core には data を書き込む場所がないため)。その結果、 overflow が発生します。これは、 user application software の書き込みが不適切であるために発生する可能性があります。もう 1 つの考えられる理由はオペレーティング システムに関連しており、これについては以下でさらに説明します。
host 上の RAM buffer のサイズは、 Xillybus IP Coreによって異なります。たとえば、このサイズは xillybus_read_32 および xillybus_write_32 ( demo bundleの一部である IP core 内) の場合は 4 MBytes です。 IP Core Factory を使用すると、非常に大きな buffersを要求するカスタム IP cores を作成できます。
結論は: overflow を防止するには、 IP coreの正しいパラメーターを選択する必要があります。 まず第一に、この IP core は data rateを処理できる必要があります。それに加えて、 hostの RAM buffer は十分な大きさである必要があります。これにより、 user application program が device fileから data を読み取っていない場合でも、データ フローを継続できます。
それでも FIFO がいっぱいになる場合、一般的な理由は system designのミスです。 overflow の一般的な理由は、 data rateを処理するコンピューターの能力を過大評価することです。
特に、 data がディスク上のファイルに書き込まれる場合 (上記の "cat" command のように)、最大 data rate は予想よりも遅くなる可能性があります。その理由は、オペレーティング システムには通常、大きな disk cache (場合によっては多数の Gigabytes) があるためです。ディスクの data rate が、 disk cacheよりも小さい量の data で測定された場合、結果は楽観的すぎます。 オペレーティング システムは、これが実際に発生する前に、 data のディスクへの書き込みが完了したふりをします。実際には、 data は cacheにしか到達せず、ディスクへの実際の書き込みは後で行われます。この間違いは、 data を大量に扱った場合にのみ明らかになります。
CPUの剥奪
残念ながら、 overflowには避けられない可能性があります。 オペレーティング システム (Linux または Windows) は、 user-space process から CPU を無期限に奪うことができます。つまり、 data を読み取るコンピューター プログラムが、突然一定期間動作を停止した後、通常の動作を再開する可能性があります。この期間に制限はありません。 non-real-time operating system は、このように processes をランダムに一時停止することができます。
それでも、 data acquisition はこれらのオペレーティング システムで引き続き使用できます。これは主に、 CPU の長期間の剥奪が一般的に悪い特性と見なされるためです。したがって、これらの一時停止は通常短いです。
これらの一時停止中、 IP core は host 上の RAM buffer を満たし続けます ( DMAのおかげで、 processorの介入は必要ありません)。コンピュータ プログラムが CPU を取り戻すと、蓄積されたすべての data をすばやく消費できます。通常、 10 ms の一時停止を補う RAM buffer で十分です。ただし、 IP Core Factoryでカスタム IP core を作成する場合は、大幅に大きい buffer を要求することができます。
とはいえ、一時停止が長すぎる可能性はまだあります。その結果、 RAM buffer がいっぱいになり、その結果、 FPGA 上の FIFO がいっぱいになります。この overflow の結果、 data が失われます。これは決して起こらないはずであり、おそらく決して起こらないでしょう。しかし、そうなったらどうしますか?
overflowの検出
推奨される解決策は、 FIFO がいっぱいになった場合に data stream を終了することです。 logic は、連続する dataの最後の要素の直後に、 EOF (end-of-file) を host に送信します。では、上記のように、 host が data を "cat" commandで消費した場合に何が起こるかを考えてみましょう。
$ cat /dev/xillybus_read_32 > capture-file.dat
通常、この command は、 CTRL-Cで停止するまで継続します。ただし、 FPGAで FIFO がいっぱいになった場合、この command は、通常のファイルのコピーが終了した後と同じように、正常に終了します。出力ファイルには、 FIFO がいっぱいになる前に収集されたすべての data が含まれます。
この方法を要約すると、次のようになります。 capture-file.dat に書き込まれるすべての data は、エラーがなく、連続していることが保証されています。 CPU の剥奪のために data acquisition システムが連続性を維持できない場合、結果として出力ファイルが短くなります。しかし、ファイルの内容は信頼できます。
このソリューションを実装するには、 dualclock_fifo_32の instantiation を次のものに置き換えます。
eof_fifo fifo_32
(
.rd_clk(bus_clk),
.rst(!user_r_read_32_open),
.rd_en(user_r_read_32_rden),
.dout(user_r_read_32_data),
.empty(user_r_read_32_empty)
.wr_clk(capture_clk),
.wr_en(capture_en),
.din(capture_data),
.full(),
.eof(user_r_read_32_eof)
);
eof_fifo の定義は別のページに記載されています。
@user_r_read_32_eof はこの FIFOの @eof portに接続されていることに注意してください。これは、必要に応じて logic が EOF を host に送信する方法です。また、この FIFOの @full portには何も接続されていないことにも注意してください。 この signal を監視する必要はもうありません。 FIFO がいっぱいになっても、対処できる方法はあまりありません。 EOF メカニズムにより、有効なデータがすべて消費された後、 host がデータ フローを再開することが保証されます。
Data playback
反対方向はどうですか?このようなものはどうですか?
$ cat playback-data.dat > /dev/xillybus_write_32
これは同じ原理で機能します: "cat" command はディスク上のファイルを読み取り、 data を device fileに書き込みます。 FPGAでは、 IP core がこの data を FIFOに書き込みます。 application logic は FIFOから data を読み取ります。考え方は同じですが、方向が逆です。
これは、 host 上の user application program から application logicまでの data flow を示す簡略化されたブロック図です。
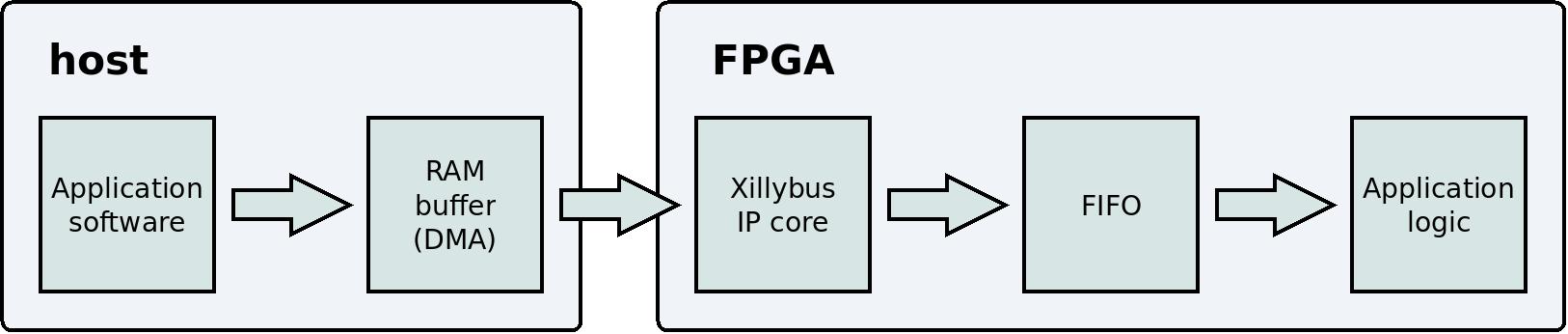
data acquisitionと同様に、 dataの損失のリスクはありません。 IP core は、いっぱいになると FIFO に書き込みません。その結果、 hostの RAM 内の buffer も満杯になる可能性があります。これが発生すると、 host 上の user application program は、 application logic が FIFOから十分な data を読み取るまで (スリープによって) 待機します。
data acquisition とのもう 1 つの類似点は、 user application program が data に十分な速さで書き込みを続ける限り、 FIFO が空になることはないということです。これを保証するために、同じ考慮事項が関連しています。 IP coreの仕様と user application program は、必要な data rateをサポートする必要があります。
これらの条件が満たされると、この data が必要なときに、 application logic は FIFO から data を消費できます。 underflow は決して起こらないはずです。
Asynchronous streams 対 Synchronous streams
このトピックは直接関係ありませんが、簡単に説明する価値があります。
data acquisition アプリケーションでは、主な目標は継続的なデータ フローを維持することです。したがって、 IP core は、 data を FIFO から hostの RAM buffer にできるだけ早く移動します。 host の user application program が特定の瞬間に data を要求しているかどうかは関係ありません ( read() への関数呼び出しなどにより)。 device file が開いていて、 FIFO内に data がある限り、データ フローは継続します。
つまり、 host は FPGA から data flow を制御する方法がありません ( device fileを開いたり閉じたりする場合、またはアプリケーション固有のソリューションに頼る場合を除く)。ただし、実際のほとんどの data acquisition アプリケーションでは、データ フローを制御する必要はありません。 device fileを開いた結果としてデータ フローが開始されるのは問題ありません。 FIFOからデータの各要素が正確にいつ読み取られたかは重要ではありません。
このように動作する device file は、 asynchronous stream ( Xillybusの用語で) と呼ばれます。
ただし、他のアプリケーションでは、 data がいつ収集されたかが重要です。たとえば、 FPGA 上の application logic は、 FIFOから data の代わりに status register のコンテンツを送信する場合があります。これは、 xillybus_mem_8という名前の device file を使用した demo bundle で実証されています。この場合、 data が FPGAでいつ収集されるかを制御することが非常に重要です。 host は、過去の不明な時点の状態ではなく、その瞬間の状態に関する情報を取得するために device file から読み取ります。
Xillybus には、この種のアプリケーション用の synchronous streams があります。 IP core は常に、 FPGAからできるだけ少ない data を収集します。言い換えると、 IP core は、 host上の read() (または同様のもの) への関数呼び出しに応答してのみ data を収集します。したがって、 data が FPGAから収集される場合、 host が制御します。
synchronous streams の欠点は、データ フローの一時停止です。これらの一時停止の主な問題は、データ フローが一時的に停止すると、 FPGA の FIFO がいっぱいになる可能性があることです。これらの一時停止により、データ フローの効率も低下するため、最大 data rate は低くなります。ただし、これら 2 つの欠点は、 data acquisition アプリケーションにのみ関係します。このようなアプリケーションでは、いずれにしても asynchronous stream を使用する必要があります。
逆方向の device files に関しては、 asynchronous streams と synchronous streamsにも違いがあります。この方向では、違いは write() 関数呼び出しの戻りにあります。 asynchronous streamsでは、 data が RAM bufferに書き込まれるとすぐに、 write() が戻ります。そのため、ほとんどの場合、 write() はまったくスリープしません。一方、 synchronous streamsでは、 write() は data が FPGAに配信されるまで待機します。これは、通信チャネルを使用してコマンドを送信する場合に重要です。しかし、繰り返しますが、これは data acquisition アプリケーションにとっては悪いことです。
demo bundleでは、 /dev/xillybus_mem_8 のみが synchronous streamです。他の 4 つの device files は asynchronous streamsです。
IP Core Factoryでは、 synchronous stream または asynchronous streams の選択はアプリケーションの選択に依存します (「use」の場合は drop-down menu )。たとえば、「Data acquisition / playback」を選択すると、ツールは asynchronous streamsを生成します。 「Command and status」を選択すると、 synchronous streamが手に入ります。 「Autoset internals」をオフにすることで、これを手動で選択することもできます。
asynchronous streams および synchronous streamsの詳細については、 programming guide for Linux (またはprogramming guide for Windows ) のセクション 2 を参照してください。 IP Core Factoryについては、 guide to defining a custom Xillybus IP coreを参照してください。
概要
シンプルでありながら実用的な data acquisition system は、 Xillybusを使用すると簡単かつ迅速に作成できます。 application software は、標準の Linux command ("cat") を使用することになります。 FPGA側では、 Xillybusの IP core とのやり取りは、 data を FIFOに書き込むことだけです。
Xillybus で収集された data は、エラーがなく、連続していることが保証されています。ただし、オペレーティング システムの性質上、 overflow が発生しないことを保証する方法はありません。これは避けられないため、最適なアプローチは、 overflow が発生した場合の検出を保証することです。 Xillybus は、 EOF を hostに送信することにより、この目的のための単純なメカニズムを提供します。